大模型时代,浅读一下LLaMA
从去年年底 ChatGPT 发布以来,大语言模型迅速升温,吸引了全世界的关注,甚至连非 IT 行业的人都知道了 ChatGPT。借着这股热潮,我也补习了一下语言模型相关的知识。这里以 Meta 开源的 LLaMA1 模型为例,通过阅读论文和代码,理解一下大语言模型的典型结构。
先了解一点背景,有助于理解 LLaMA 模型。当前主流的大语言模型,都是基于谷歌提出的 Transformer2(后文称为经典 Transformer)。Transformer 的关键贡献是引入了 attention 机制来处理上下文之间的关联性。在自然语言中,如何理解一段文本中的某个词是取决于上下文的,并且上下文中的每个词对当前词含义的影响程度也是不同的。在 Transformer 之前,这种关联性是通过 RNN 来处理的。但是 RNN 必须按顺序处理每个词,不能并行计算,attention 解决了这个问题。关于 Transformer 和 attention,这里先不展开,后面结合代码来看。
经典 Transformer 是 encoder-decoder 架构,encoder 处理输入,将其转换成状态,decoder 根据状态产生输出。形象一点的说,encoder 负责理解问题,decoder 负责做出应答。根据初代 GPT 发表的论文3,GPT 是 decoder-only 的 Transformer。LLaMA 的论文里虽然没有说,但是从代码来看,也是一样只有 decoder。至于为什么采用 decoder-only 模型,这里4有篇文章我觉得分析得很好。
相比经典 Transformer,LLaMA 做了以下三点改动:
- Pre-normalization。在每一个 sub-layer 里,对输入进行 normalize,而不是对输出。使用的函数为 RMSNorm。
- SwiGLU activation function。在前馈神经网络里,使用 SwiGLU 激活函数,而不是 ReLU。
- Rotary Embeddings。用 rotary positional embeddings(RoPE)取代 absolute positional embeddings。
这三点改动并非 LLaMA 原创,而是来自之前的文献。想要深入了解需要去阅读原始文献。
接下来结合pyllama代码来解读一下 LLaMA 模型,不用原版代码是因为里面有一些并行优化,pyllama 里提供了一个单机版本(llama/model_single.py),更容易理解。
我们用自顶向下的方式来看模型结构。最顶层的类是Transformer,__init__()是构造函数,负责构造模型的各个组件,forward()是推理计算过程,描述了组件之间如何连接。首先是 tok_embedding(torch.nn.Embedding),用来把输入 token 转换成 embedding 向量;接下来是若干层串联的 TransformerBlock,然后经过 norm(RMSNorm)归一化,最后是一个全连接层 output(torch.nn.Linear)。连接示意图如下:
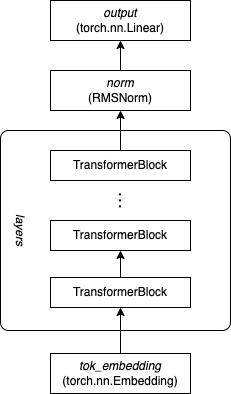
TransformerBlock 类是模型的基本结构,每个单元包含两个 sub-layer:一个 multi-head self-attention(self.attention)和一个前馈神经网络(self.feed_forward)。除此之外还有两个 RMSNorm 层 self.attention_norm 和 self.ffn_norm 用来进行归一化。连接方式如下图(1)所示:
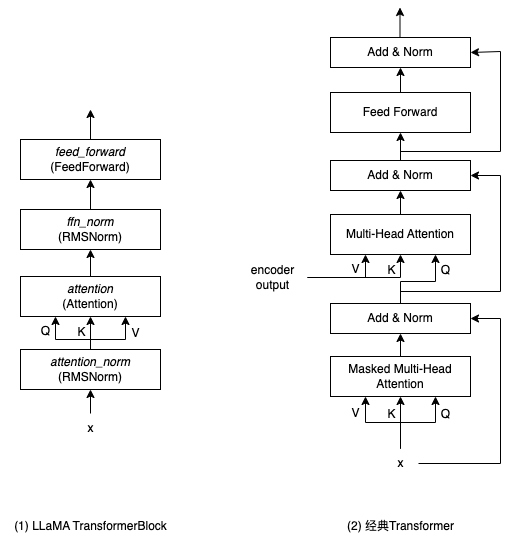
上图(2)是经典 Transformer 里 decoder 每一层的结构,对比来看,经典 Transformer 对 attention 和前馈神经网络的输出进行归一化,而这里 LLaMA 是对输入进行归一化。这就是前文的三点改动中的 Pre-normalization。还有一点区别是:在经典 Transformer 里,每个 sub-layer 的输出会经过 dropout 再跟输入相加,然后再进行归一化,LLaMA 对这里也进行了简化,去掉了残差结构。另外,由于没有 encoder,所以用 encoder 输出作为输入的第二层 attention 也去掉了。
Attention 比较复杂一点,放在最后。先看FeedForward 类,其中有 3 个全连接层 w1、w2 和 w3。推理计算公式如下:
\(FF(x) = w_2(silu(w_1(x)) \times w_3(x))\)其中 silu 就是 swish 激活函数,这里对应了前文说的第 2 点改动。在经典 Transformer 里,前馈神经网络是两个全连接层中间加上 ReLU 激活函数(见论文 3.3 节),计算公式如下:
\(FF(x) = w_2(ReLU(w_1(x)))\)最后是Attention 类,主要是 4 个全连接层 wq、wk、wv、wo 构成,结构如下图(3)所示。
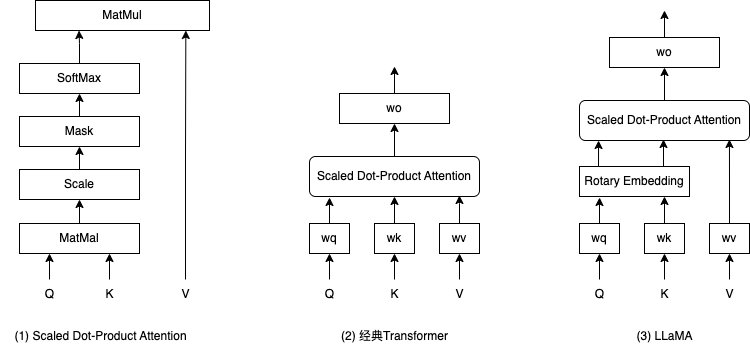
LLaMA 跟经典 Transformer 一样,使用的都是 scaled dot-production attention,如上图(1)所示。在经典 Transformer 中,输入向量 x 分别经过 3 个全连接层 wq、wk、wv 得到三个值 q、k、v 作为 attention 的输入,attention 的输出在经过全连接层 wo 得到最终输出。LLaMA 的区别是,在 wq 和 wk 之后,还多了一层 Rotary Embedding,这就是前文说的改动点 3。
再说一下 milti-head,其实就是把输入的 q、k、v 划分到不同的子空间里(也就是分成若干段),分别计算 attention,再把各个子空间的 attention 拼接到一起。每一个子空间是独立计算的,因此可以理解为,不同子空间代表了输入数据之间不同维度的相关性。
这个模型结构看起来也并不复杂,为什么现在的大模型动辄几十亿参数起步呢?我们以 LLaMA-7B 模型为例,看看这 70 亿参数都用在哪里了。下面是模型里的params.json文件:
{
"dim": 4096,
"multiple_of": 256,
"n_heads": 32,
"n_layers": 32,
"norm_eps": 1e-6,
"vocab_size": -1
}
这里影响模型规模的参数有 3 个:dim、multiple_of 和 n_layers。其中 dim 决定了 Attention 的参数数量,dim 和 multiple_of 决定了 FeedForward 前馈神经网络的参数数量,n_layers 决定了 Transformer 的层数。
Attention 里的四个全连接层 wq、wk、wv、wo,shape 都是(dim, dim),所以一共有 \(4096 \times 4096 \times 4 = 67,108,864\) 个参数。
FeedForward 里的三个全连接层,shape 分别是(dim, hidden_dim)、(hidden_dim, dim)和(hidden_dim, dim),其中 hidden_dim 的值为 \((dim \times 4) \times {2\over3}\) 然后按 multiple_of 对齐,在 LLaMA-7B 里就是 11008,FeedForward 的参数数量为 \(4096 \times 11008 \times 3 = 135,266,304\) 。
32 层的参数总量为 \((67,108,864 + 135,266,304) \times 32 = 6,476,005,376\) ,大约 65 亿,7B 大概就是这么来的。其他还有一些参数(比如 RMSNorm)相对就很少了,可以忽略不计。
小结一下,这篇文章主要是结合论文和代码,简单解读了一下 LLaMA 模型的结构,以及它和经典 Transformer 的区别。水平有限,未能深入探究各个设计细节以及背后的思想,留待以后继续学习。