向量检索在推荐系统中的应用
个性化推荐通常分成 2 个阶段:召回和排序。召回是从全量库中粗选出一些用户可能感兴趣的 item,排序则是对召回的结果进行更精细的打分排序从而得到最终的推荐结果。
当前应用很广泛的一种召回方式,是谷歌 2019 年提出的双塔模型。该模型源自微软 2013 年提出的 DSSM1。DSSM 是用于网页搜索的,谷歌在 2019 年的一篇论文2里把它用在了推荐系统里,并且提出了“双塔”这个叫法。双塔模型现在已经被很多公司采用,Facebook、百度等公司都在双塔模型的基础上做了自己的改进。
双塔模型的核心是把推荐问题转换成向量检索问题,从而实现实时的个性化推荐。下图是谷歌论文中的配图,描述了 YouTube 使用的双塔模型。
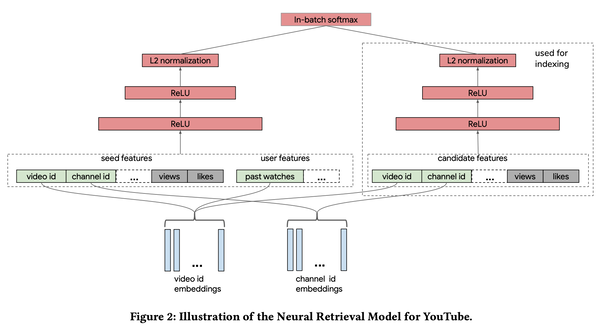
双塔模型是一个监督学习模型,训练样本是<x, y, r>的三元组形式,其中 x 是左塔的输入,包括了用户信息和上下文信息,比如用户的性别、年龄、登录设备等,以及当前正在观看的视频和最近观看过的视频。这些数据经过先期 embedding 之后再拼接组成一个大的特征向量,就是 x。y 是右塔的输入,即 item(视频)信息;r 是用户和视频的相关度,可以用点击后观看视频的时长来评分,例如全部看完就是 1,看得时间很短就是 0。
训练样本是从线上用户的点击流中得到的,只有用户点击过推荐的视频之后才会被记录,因此原始数据都是正样本。在训练的时候需要人工构造负样本。如果用随机采样的方式构造负样本,在训练样本中数据分布倾斜严重的情况下,会导致模型性能较差。谷歌在论文中提出了相应的解决办法,这里不展开讲。
左塔和右塔的输出分别是用户和 item 的 embedding 向量,二者具有相同的维度。计算两个向量的相似度 s(x,y),再经过一个 softmax 层,就得到了模型的输出。Softmax 通常用来解决多分类问题,输出是一个概率分布,这里是把推荐问题当做分类问题来处理了。例如要在 M 个 item 中进行推荐,softmax 层的输出就是 M 维向量,每个分量代表了对应的 item 被推荐的概率。
双塔模型的损失函数如下图所示:
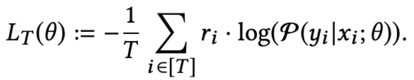
这里使用的是对数似然函数作为损失函数,log()里的部分就是 softmax 函数,展开如下:
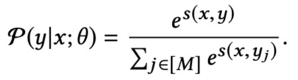
模型的训练过程,就是损失函数的值最小化的过程,也就是在 s(x, y)和 r 之间建立相关性的过程。训练完成之后,将右塔的输出作为 item 的特征向量存储到向量检索服务(例如 Milvus)中,就可以用作线上的实时推荐。用户观看某个视频时,将用户信息输入模型的左塔得到 embedding 向量,然后去向量检索服务中进行近似最近邻检索,就可以得到召回结果。
双塔模型聪明的地方在于,它在两组独立的输入(user 和 item)之间建立关联,使得二者的 embedding 向量(即左塔和右塔的输出)的相似度和推荐度(即训练数据中的 r)呈正相关,从而把个性化推荐中的召回转换成向量检索问题。推而广之,除了推荐系统之外,是不是任何需要在两组独立输入之间建立关联的问题,都可以使用类似的双塔模型,将其转换成向量相似度的问题?类似的场景还有哪些?